
Skyrocket Your Bug Bounty Success Using These Crawlers
Struggling to find vulnerabilities that pay good bounties? You might be missing the key ingredient in your toolkit. Discover the secret weapons of top-tier bug bounty hunters – the top crawlers used in the industry. Skipping this means leaving the money on the table. Dive in to discover these powerful crawlers that can skyrocket your bug bounty success, starting today.
What is the difference between an average hunter and a successful hunter? It’s the tools that could reveal what others miss. We will be exploring the different tools, how fast they are, and the amount of data we can gather, discovering vulnerabilities faster than ever before, and tapping into hidden areas of web applications. This could be a true gold mine. Stay tuned as we deep dive into the functionalities of these crawlers.
Preparing Targets
I will be using root directories collected from the subdomain recon. Feel free to check my first couple of videos on the recon playlist if you want to know how I did that. It’s a good starting point for the crawlers, but you might want to exclude certain endpoints. Alternatively, you could use hosts from httpx output or any other alive host collecting tool. For this type of output, I would like to filter out ones with status code 200 and add them to the to-crawl.txt file manually.
I have collected around 200 lines from both gau endpoints and httpx hosts. This will be a pretty good start for different crawlers to test their capabilities. I will also show you how to employ those tools with axiom.
Tool #1 – Katana
The first tool that I’m going to test is Katana by Project Discovery. It has a lot of functionality. My goal here is to test how many endpoints I could collect using different flags and compare them.
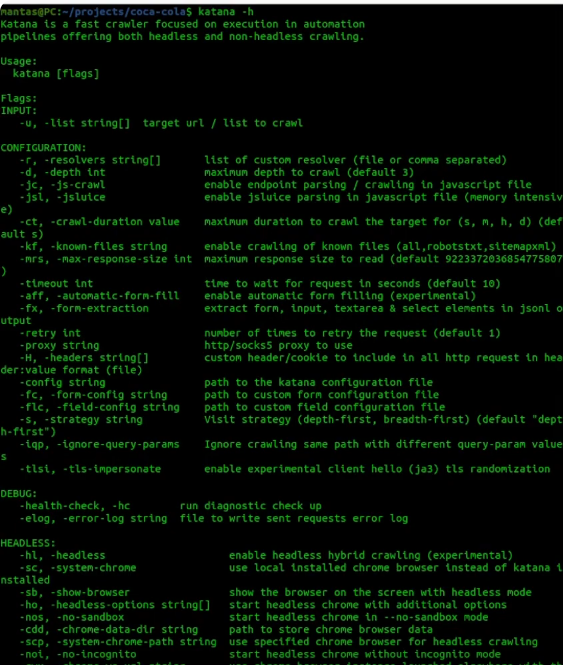
I will be using js crawling, have some limitations for the crawl duration – 1 hour, automatic form fill, and form extraction. I will compare 3 different cases:
- Using a depth-first strategy:
katana -u to-crawl.txt -d 5 -jc -ct 1h -aff -fx -s depth-first -o katana-df.txt - Crawl with a breadth-first strategy:
katana -u to-crawl.txt -d 5 -jc -ct 1h -aff -fx -s breadth-first -o katana-bf.txt - Using a headless mode:
katana -u to-crawl.txt -d 5 -jc -ct 1h -aff -fx -headless -o katana-headless.txt
So let’s try to run them piece by piece measuring the runtime by time command and comparing the outputs as well:
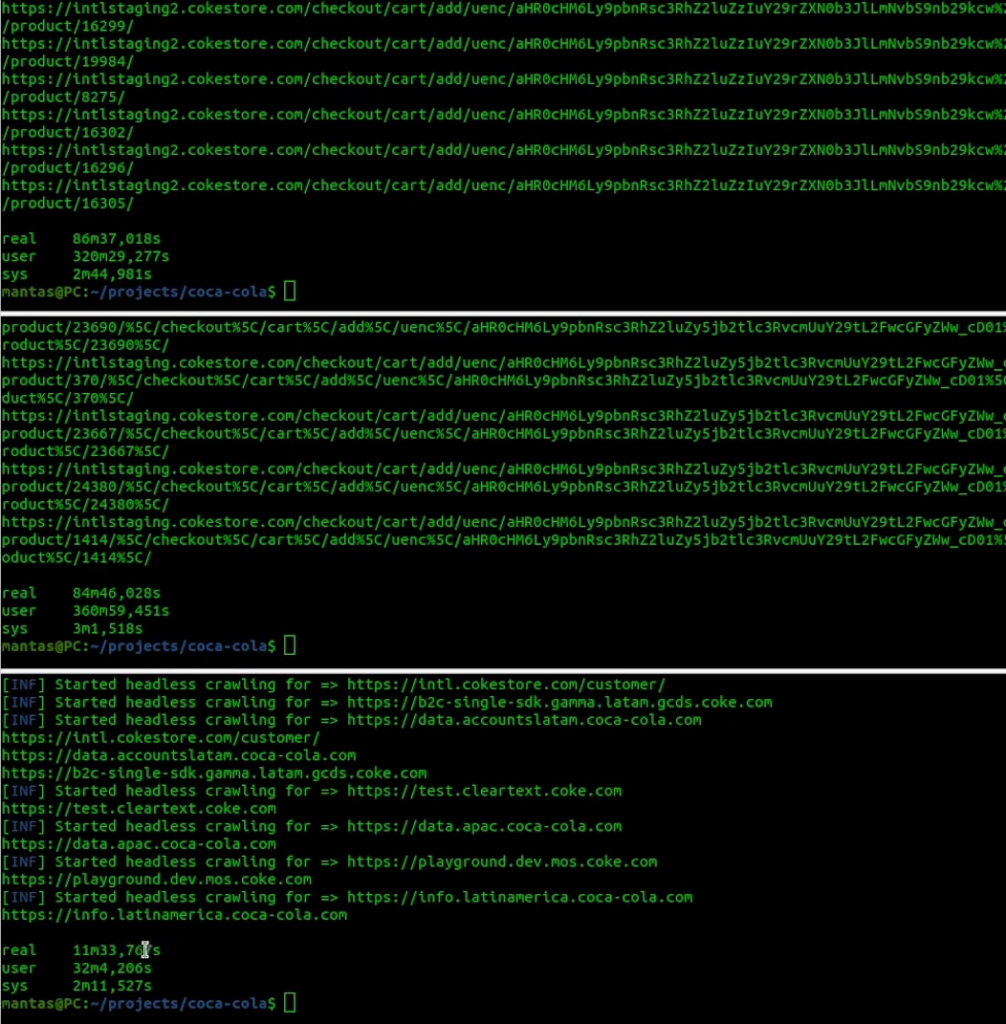
To my surprise, the -headless option (the last output) took less amount of time to finish, but it probably collected fewer endpoints than the other two options. Those two options ran in 1 and a half hours almost and collected quite a lot of endpoints from 200 hosts. So if you want to run even faster you can play around with those parameters, but keep in mind, that if you go too aggressive it could trigger a WAF and all of your requests will be blocked.
We could also try running katana with AXIOM! I will be using this module with 20 instances:
[{
"command":"/home/op/go/bin/katana -u _target_ -jc -nc -silent -f qurl -kf -fx -retry 3 -d 5 -aff -ct 1h -o _output_/_cleantarget_",
"ext":"txt",
"threads":"3"
}]I will use this one to extract URLs with parameters. Also, I have added retries. All other options are pretty similar, so let’s try to run it using the following command:
axiom-scan to-crawl.txt -m katana -o katana-axiom.txtTo my surprise, 20 axiom instances took more than an hour to finish crawling on all of those targets:
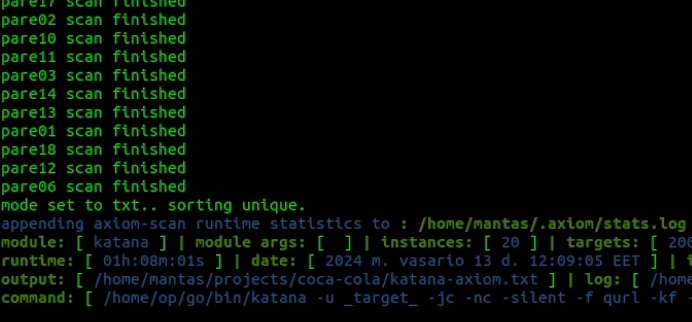
I was expecting to be 20 times faster but it went pretty much similar compared to the other results. There are a couple of reasons for that:
You will never know how much time is needed to crawl one host. So sometimes the blog, e-commerce, and documentation websites have thousands or even millions of endpoints. For that case, to limit the crawl time I have chosen 1 hour max time for the host. For axiom to run more efficiently – you should decrease it by around 15 minutes or even less using -ct flag.
Some target hosts might be available in the United States (or any other country). For example, my VPS servers are also located in the United States. That’s why many of those sites were accessible and they crawled much more results.
To bypass country restrictions if you are running from your laptop, I suggest installing some kind of VPN software. For example, I use Nordvpn, since they have a pretty nice CLI tool as well. It’s very convenient since I have tried multiple VPS providers and this one has so many locations that you can switch its speed is pretty awesome!
Tool #2 – Hakrawler
The second crawler is hakrawler. It’s a little bit less configurable, but sometimes the less this is more. It has enough parameters to not give me ADHD. Let’s try running it so using pretty much the same configuration:
cat to-crawl.txt | hakrawler -d 5 -dr -insecure -t 10 -timeout 3600 | tee hakrawler.txtAs you can see, I will use a depth of five, do not follow redirects, insecure flag, just in case I have some SSL issues, the same amount of threads, and also timeout is 1 hour.
The final results of this tool looked like this:
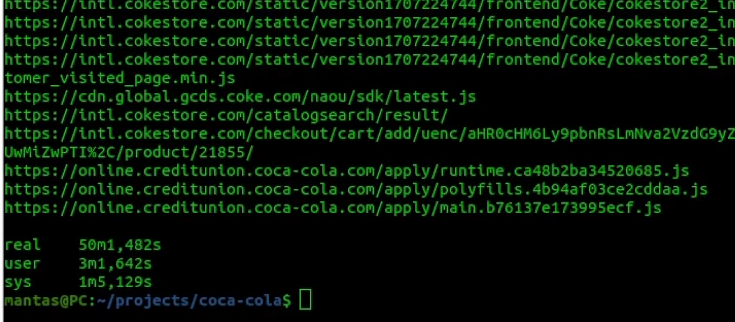
The hakrawler has finished running and it’s much faster than the previous tool. It’s written in Golang as well and from the speed perspective, it’s very good language to run on. Right now let’s try running with 20 AXIOM instances, using the same parameters as before:
axiom-scan to-crawl.txt -m hakrawler -o hakrawler-axiom.txtSo let’s run and see the results:
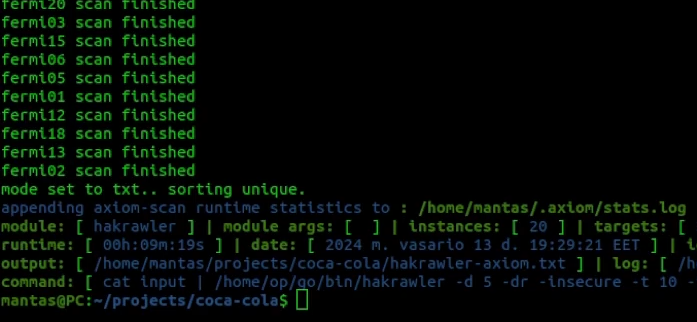
To my surprise, it only took less than 10 minutes. It’s the fastest run time so far but is this tool used with AXIOM collected enough amount of endpoints?
Tool #3 – Gospider
The last command line tool to try is gospider. It’s another tool written in the Go language. It should be pretty fast for this case. It has more parameters than the second tool but I think it lacks the most crucial one – I don’t see the maximum amount of runtime for the URL parameter. For this reason, I predict it could run a lot of time or even crash but let’s put this tool to the test:
gospider -S to-crawl.txt -q -d 5 -c 10 --sitemap --no-redirect -o gospider.txtThe gospider took over 2 hours to complete:

Hopefully, it had discovered a lot of endpoints. I imagine that this tool could have run even more time if it passed more hosts because there is no limitation on the amount of time to run on a single URL… Now let’s see how fast it can be if we implement it using AXIOM as well:
axiom-scan to-crawl.txt -m gospider -o gospider-axiom.txtIt took only 23 minutes and 40 seconds to finish its run time:

In this case, using gospider with AXIOM is six times faster with 20 machines.
Bonus: Burp Spider
The last crawler we going to try is the burp spider. This is my favorite so far but for it to be efficient you have to have a pretty damn good computer. Unfortunately, my computer is pretty old but I guess for a simple crawling it will be pretty much okay… Before that, we need to set the scope. Go to target -> scope settings, use advanced control and we can use “load” and try to load those wildcards:
I suggest adding wildcards.txt for this one:
Now go to the dashboard -> new scan -> crawl:
I want to load URLs to scan. I will try to cat that to-crawl.txt file and use xclip utility with selection and copy:
cat to-crawl.txt | xclip -selection copyFor 200 URLs it will be pretty much okay. Paste it to the URLs to scan section:

Try to edit the scan configuration here:
Let’s name this configuration – Crawler, use five-link depth, and have to set some limitations:
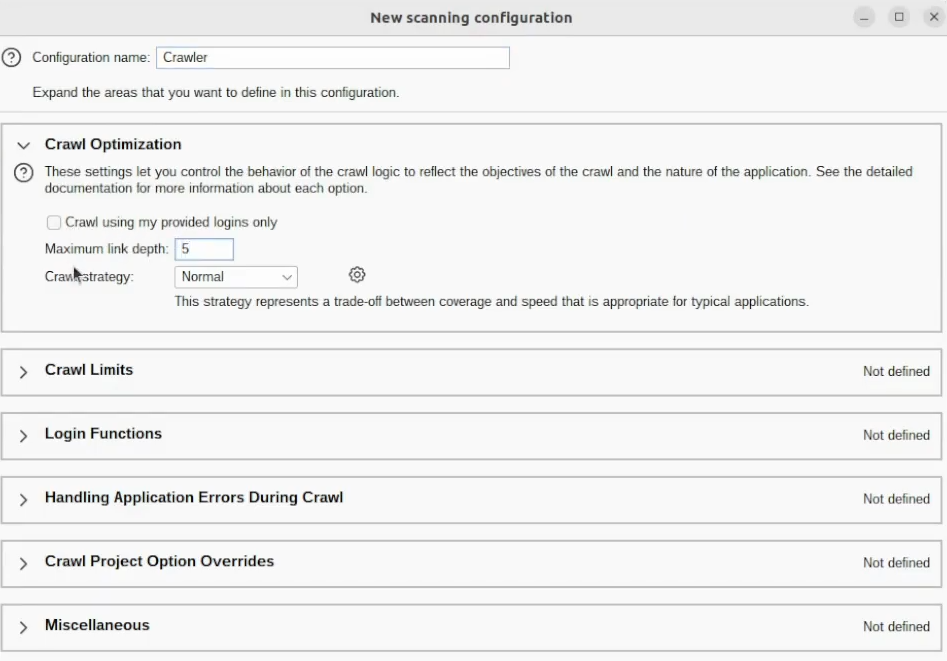
The max crawl duration I want to be – 600 minutes. and unique location discovered at 150000:

Leave other settings as default, try to save it, and run it. After the crawler has finished running, I want to export the results. There is a neat trick on how you can export the collected endpoints – you can use the GAP extension. It does require Python and jython to be installed and it has to be linked as well.
Go to the Target tab, select all those collected endpoints and send to the GAP:

We have to wait until it loads. I have selected what I only want links, waited for it to fully load, and filtered by In scope only:
There are a lot of junk results, so might want to only include those who have https. Hit the ctrl+c and place them into gap.txt. I suggest when working with burp – the best way is just getting to the Target Tab just viewing results right there, and not using any other third-party tools… Unless you want to pass for extra checks. That could be pretty good idea, but for this case – I only use burp while I’m testing manually and using that crawler to run in the background.
Final Crawler Results
I have filtered out some results manually for better comparison. I had to do this, since some tools gave me a bunch of garbage endpoints or paths with non 200 status code. Also, there were endpoints starting with javascript:void, email or phone. While this might be interesting area to look and check for leaks but this might not be in the scope for this writeup. So I only have collected the unique URLs, starting with HTTP keyword.
Crawlers by The Number of Endpoints:
- Gospider – 80497
- Gospider with axiom – 74544
- Katana with breath-first strategy – 54773
- Hakrawler with axiom – 41184
- Hakrawler – 40127
- Katana with depth-first strategy – 37974
- Burp using GAP extension – 9797
- Katana with axiom – 4116
- Katana with headless mode – 1575
Crawlers by The Runtime:
- Hakrawler with axiom – 9m 19s
- Katana with headless mode – 11m 33s
- Gospider with axiom – 23m 40s
- Hakrawler – 50m 1s
- Katana with axiom – 1h 8m 1s
- Katana with breath-first strategy – 1h 24m 46s
- Katana with depth-first strategy – 1h 26m 37s
- Gospider – 2h 7m 21s
- Burp Spider – 10h
Top Crawlers From Combined Results:
1-2 Gospider with axiom or Hakrawler with axiom
3-5 Gospider/Hakrawler/Katana breath-first
6-9 Other Katana strategies/Burp
Last Thoughts
If you find this information useful, please share this article on your social media, I will greatly appreciate it! I am active on Twitter, check out some content I post there daily! If you are interested in video content, check my YouTube. Also, if you want to reach me personally, you can visit my Discord server. Cheers!